
—
0:00
Mamba Architecture Survey: The Complete Guide to State Space Models Beyond Transformers
Table of Contents
- What Is Mamba? A New Foundation Model Architecture
- Mamba vs. Transformers: Understanding the Computational Advantage
- State Space Models: The Mathematical Foundation of Mamba
- Mamba Block Design and Architecture Innovations
- Mamba for Computer Vision: Vision Mamba and Beyond
- Mamba for Natural Language Processing and Language Modeling
- Adapting Mamba to Diverse Data Types
- Mamba in Healthcare and Biomedical Applications
- Challenges and Future Research Directions for Mamba
- Mamba’s Impact on the AI Architecture Landscape
🔑 Key Takeaways
- What Is Mamba? A New Foundation Model Architecture — In the rapidly evolving landscape of deep learning, a new architecture has emerged that challenges the long-standing dominance of Transformers: Mamba.
- Mamba vs. Transformers: Understanding the Computational Advantage — The central technical innovation of Mamba lies in how it processes sequential information compared to Transformer architectures.
- State Space Models: The Mathematical Foundation of Mamba — To understand Mamba’s architecture, it’s essential to grasp the state space model framework from which it derives.
- Mamba Block Design and Architecture Innovations — The survey categorizes Mamba architecture innovations into three critical dimensions: block design, scanning modes, and memory management.
- Mamba for Computer Vision: Vision Mamba and Beyond — One of the most active application areas for the Mamba architecture is computer vision, where the quadratic complexity of Vision Transformers has long been a practical limitation for high-resolution image processing.
What Is Mamba? A New Foundation Model Architecture
In the rapidly evolving landscape of deep learning, a new architecture has emerged that challenges the long-standing dominance of Transformers: Mamba. Built on structured state space models (SSMs), Mamba delivers comparable modeling capabilities to Transformer-based systems while maintaining near-linear scalability with sequence length—a fundamental advantage that addresses one of the most critical limitations of attention-based architectures. This comprehensive survey from researchers at Hong Kong Polytechnic University and Vanderbilt University systematically reviews the explosion of Mamba-related research across architecture design, data adaptability, and real-world applications.
The significance of Mamba cannot be overstated. While Transformers have powered the most impressive AI advances of the past decade—from GPT-4 to DALL-E—their quadratic computational complexity in attention calculation creates a fundamental bottleneck. Processing a sequence of length N requires O(N²) computation, making long-document analysis, high-resolution image processing, and genomic sequence modeling either prohibitively expensive or entirely infeasible. Mamba’s linear O(N) complexity transforms what is possible, enabling practical processing of sequences that would overwhelm even the most powerful Transformer implementations.
The architecture draws inspiration from classical state space models in control theory, combining the sequential processing strengths of recurrent neural networks with the parallel computation capabilities of convolutional networks. This hybrid foundation, enhanced by Mamba’s novel selective mechanism, creates an architecture that is simultaneously efficient, expressive, and practically deployable at scale. For readers seeking context on the Transformer architectures that Mamba complements, our guide on large language model capabilities and limitations provides essential background.
Mamba vs. Transformers: Understanding the Computational Advantage
The central technical innovation of Mamba lies in how it processes sequential information compared to Transformer architectures. Transformers use self-attention mechanisms that compute relationships between every pair of positions in a sequence—a powerful approach that captures global dependencies but scales quadratically with input length. For a sequence of 1,000 tokens, this means 1,000,000 pairwise computations; for 10,000 tokens, it explodes to 100,000,000.
Mamba replaces this attention mechanism with a selective state space model that processes sequences through a hidden state, updating this state at each step based on input-dependent parameters. The “selective” innovation is crucial: unlike earlier SSMs that used fixed parameters regardless of input, Mamba parameterizes its state space transitions based on the current input, enabling the model to dynamically decide what information to retain and what to discard. This input-dependent selection achieves the contextual understanding of attention without its computational burden.
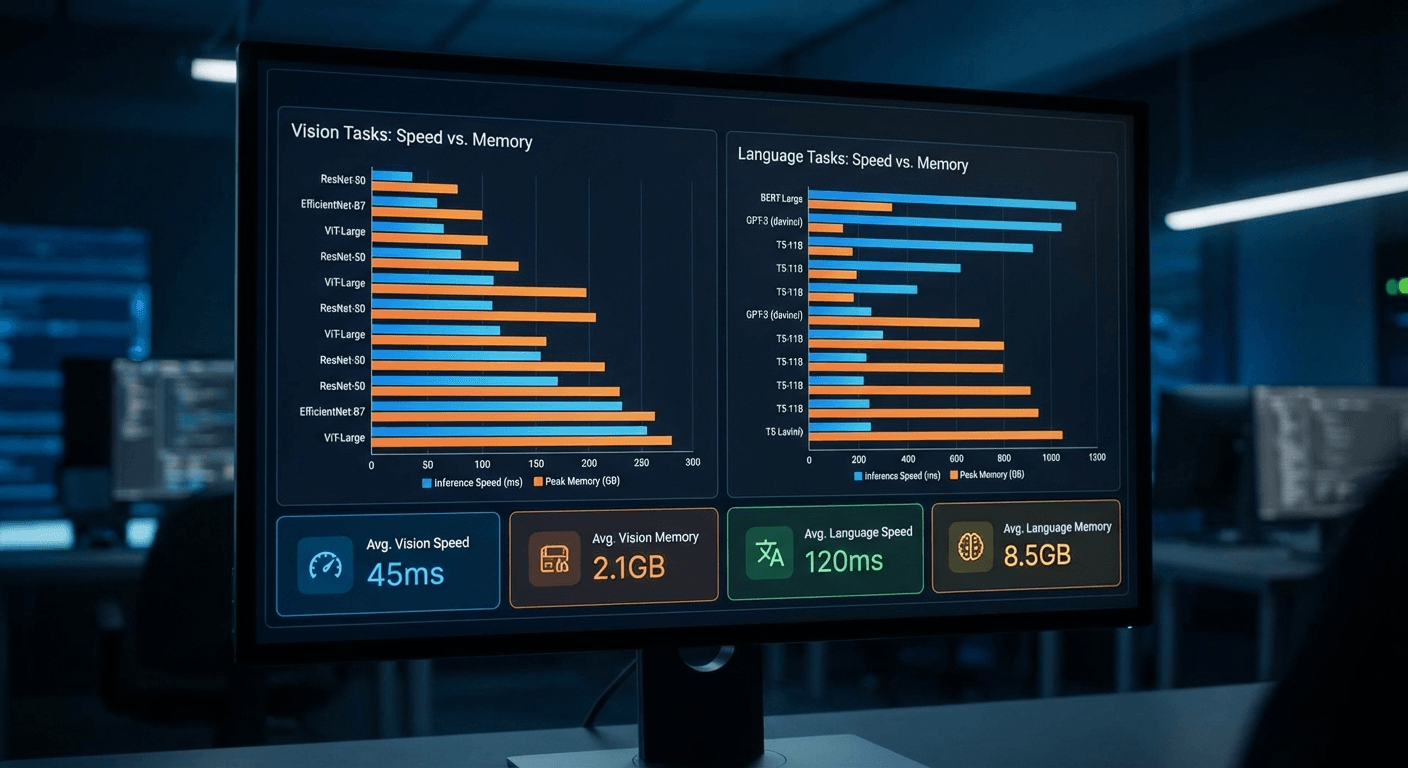
The practical performance differences are dramatic. The survey reports that Vision Mamba (Vim) is 2.8× faster than DeiT (a leading vision Transformer) and saves 86.8% GPU memory when processing high-resolution images. Mamba-2 achieves 2-8× speedup on language modeling compared to standard approaches. These aren’t marginal improvements—they represent fundamental shifts in what’s computationally feasible, enabling new applications that were previously impossible due to memory and speed constraints.

State Space Models: The Mathematical Foundation of Mamba
To understand Mamba’s architecture, it’s essential to grasp the state space model framework from which it derives. State space models are a classical mathematical formalization used in control theory to describe dynamic systems through hidden state variables. In their continuous form, an SSM maps an input signal x(t) through a hidden state h(t) to an output y(t) using four parameter matrices: A (state transition), B (input projection), C (output projection), and D (skip connection).
The key insight that enabled SSMs for deep learning was the Structured State Space (S4) model, which showed that by discretizing these continuous equations and imposing specific structural constraints on the A matrix, SSMs could be computed efficiently using either recurrent operations (for fast inference) or convolutional operations (for fast training). This dual computation mode gives SSMs a unique advantage: they can be trained in parallel like Transformers but deployed as efficiently as RNNs.
Mamba’s breakthrough builds on this foundation by making the B, C, and discretization step parameters input-dependent rather than fixed. This seemingly simple change has profound implications: it transforms the SSM from a linear time-invariant (LTI) system to a time-varying system that can selectively process information based on context. However, this input-dependence also breaks the convolutional computation mode used during training. Mamba resolves this with a novel hardware-aware algorithm that computes the recurrence efficiently using a parallel scan operation, achieving up to 3× faster computation on modern GPUs compared to naive implementations.
📊 Explore this analysis with interactive data visualizations
Mamba Block Design and Architecture Innovations
The survey categorizes Mamba architecture innovations into three critical dimensions: block design, scanning modes, and memory management. Each dimension represents an active area of research where the community is pushing the boundaries of what Mamba-based models can achieve.
Block design encompasses how Mamba layers are structured and composed within larger models. The standard Mamba block consists of a linear projection that expands the input dimension, a 1D convolution for local feature extraction, the selective SSM core, and a gating mechanism with SiLU activation. Researchers have developed numerous variations, including hybrid blocks that combine Mamba layers with attention layers to capture both local and global patterns, residual Mamba blocks that improve gradient flow in deep networks, and multi-scale Mamba blocks that process information at different temporal resolutions simultaneously.
Scanning modes define how multi-dimensional data (such as images or graphs) is converted into sequences for processing by the fundamentally sequential Mamba architecture. While text naturally forms a sequence, images, 3D point clouds, and graph structures require carefully designed scanning strategies. The survey documents innovations including bidirectional scanning (processing sequences in both forward and reverse directions), cross-scanning (traversing 2D images along multiple paths), and hierarchical scanning (processing data at progressively finer granularity). These scanning innovations are critical for extending Mamba’s advantages beyond natural language processing to computer vision and beyond.
Memory management addresses how Mamba models efficiently handle their hidden states across long sequences. Unlike Transformers that maintain explicit key-value caches that grow linearly with sequence length, Mamba compresses all historical information into a fixed-size hidden state. This provides constant memory usage during inference, regardless of sequence length—a fundamental advantage for deployment scenarios where memory is constrained or sequence lengths are unpredictable.
Mamba for Computer Vision: Vision Mamba and Beyond
One of the most active application areas for the Mamba architecture is computer vision, where the quadratic complexity of Vision Transformers has long been a practical limitation for high-resolution image processing. The survey documents a proliferation of Mamba-based vision models that achieve competitive or superior performance to Transformer counterparts with dramatically lower computational costs.
Vision Mamba (Vim), proposed by Zhu et al., adapts the Mamba architecture for image classification by treating images as sequences of patches—similar to Vision Transformers—but processing them through selective state space layers instead of attention. The results are striking: Vim achieves comparable accuracy to DeiT while being 2.8× faster and using 86.8% less GPU memory. These efficiency gains are particularly significant for processing high-resolution medical images, satellite imagery, and video where Transformers quickly exceed available GPU memory.
UMamba demonstrates Mamba’s potential in medical image segmentation, one of the most important practical applications in healthcare AI. By replacing Transformer blocks with Mamba blocks in U-Net-style architectures, UMamba achieves state-of-the-art segmentation performance on radiology benchmarks while dramatically reducing inference time and memory requirements. This makes real-time medical image analysis more feasible in clinical settings where computational resources are limited. Our analysis of efficient LLM architectures explores similar efficiency-focused innovations in the language domain that complement Mamba’s vision advances.
Mamba for Natural Language Processing and Language Modeling
While Transformers currently dominate natural language processing through models like GPT-4 and Claude, Mamba’s linear scalability positions it as a compelling alternative for next-generation language models. The survey reviews several key developments in Mamba-based language processing that suggest a significant shift in the architecture landscape.
Mamba-2, developed by Dao and Gu, represents the most significant evolution of the core architecture for language tasks. By revealing deep connections between selective state space models and variants of attention, Mamba-2 achieves 2-8× speedup on language modeling while maintaining competitive perplexity scores. The architecture demonstrates that the expressive power traditionally attributed to attention mechanisms can be achieved through different computational primitives, opening new possibilities for efficient language model design.
The implications for large language model scaling are profound. Current frontier LLMs face diminishing returns as context windows grow longer—processing a 1 million token context with Transformers requires enormous computational resources. Mamba’s linear scaling means that doubling the context length only doubles the computation, rather than quadrupling it. This property is essential for applications requiring processing of entire codebases, complete books, or extensive document collections. As our coverage of the McKinsey State of AI 2024 highlights, the demand for longer context windows and more efficient inference is driving significant investment in alternative architectures like Mamba.
📊 Explore this analysis with interactive data visualizations
Adapting Mamba to Diverse Data Types
A key strength of the Mamba architecture documented in the survey is its adaptability to fundamentally different data types beyond sequential text and image patches. The survey categorizes data adaptation techniques into sequential and non-sequential approaches, each requiring specialized strategies to leverage Mamba’s advantages.
For sequential data, Mamba naturally excels. Time-series analysis, audio processing, genomic sequences, and video understanding all benefit from Mamba’s ability to efficiently model long-range dependencies with linear complexity. In genomics, where DNA sequences can span millions of base pairs, Mamba’s linear scalability enables analysis at scales that are completely impractical with Transformer-based approaches. In time-series forecasting, Mamba models have demonstrated competitive accuracy with significantly lower latency, making real-time prediction feasible for financial markets, sensor networks, and climate modeling.
For non-sequential data, the challenge is more nuanced. Graph-structured data, 3D point clouds, and tabular data lack a natural sequential ordering, requiring careful design of serialization strategies. The survey documents innovations in graph Mamba models that use graph traversal algorithms to convert graphs into sequences while preserving structural information. Similarly, point cloud Mamba models employ space-filling curves (like Hilbert curves) to linearize 3D spatial data while maintaining locality. These data adaptation techniques expand Mamba’s applicability far beyond its original sequential processing focus, positioning it as a general-purpose foundation architecture. For broader context on AI architecture evolution, the Accenture Technology Vision 2025 provides enterprise perspectives on how these architectural innovations translate to business applications.
Mamba in Healthcare and Biomedical Applications
Healthcare represents one of the most promising and impactful application domains for Mamba architecture, where the combination of long sequence processing and computational efficiency addresses critical practical constraints. The survey identifies several healthcare applications where Mamba-based models are achieving breakthrough results.
In medical imaging, Mamba architectures are transforming the efficiency-accuracy trade-off for radiology, pathology, and ophthalmology applications. Traditional deep learning models for medical image analysis, particularly those based on Vision Transformers, require substantial GPU resources that limit deployment in clinical settings—especially in resource-constrained healthcare systems in developing countries. Mamba-based models like UMamba achieve comparable diagnostic accuracy while requiring a fraction of the computational resources, making advanced AI-assisted diagnosis more broadly accessible.
In genomics and drug discovery, Mamba’s ability to process extremely long sequences is uniquely valuable. DNA sequences, protein structures, and molecular interaction networks all involve data of a scale that challenges Transformer architectures. Mamba’s linear scalability enables end-to-end processing of entire gene sequences and large molecular datasets, potentially accelerating drug discovery pipelines and enabling more comprehensive genomic analysis for precision medicine applications.
Challenges and Future Research Directions for Mamba
Despite its impressive capabilities, the survey identifies several critical challenges and open research questions for the Mamba architecture. Understanding these limitations is essential for researchers and practitioners evaluating Mamba for their applications.
Theoretical understanding of why Mamba works as well as it does remains incomplete. While empirical results consistently demonstrate competitive performance with Transformers, the theoretical foundations explaining Mamba’s expressive power—particularly the role of the selective mechanism in approximating attention-like computations—require further development. This theoretical gap limits the community’s ability to predict when and why Mamba will outperform or underperform relative to alternatives.
Scaling behavior is another critical uncertainty. While Mamba has been validated at moderate scales, the behavior of Mamba-based models when scaled to billions of parameters—comparable to frontier LLMs—is not yet well-characterized. Whether Mamba’s advantages persist, diminish, or amplify at extreme scale is a question with significant implications for the future of AI architecture. Some researchers hypothesize that hybrid architectures combining Mamba layers for efficiency with attention layers for critical reasoning steps may represent the optimal design point.
Training dynamics present practical challenges. Mamba’s selective mechanism, while powerful during inference, introduces training complexity that requires careful hyperparameter tuning and initialization strategies. The hardware-aware algorithm that enables efficient computation on GPUs is currently optimized for NVIDIA A100 GPUs, and adaptation to other hardware platforms (including TPUs and emerging AI accelerators) remains an active engineering challenge.
Mamba’s Impact on the AI Architecture Landscape
The emergence of Mamba represents a pivotal moment in the evolution of deep learning architectures. For the first time since the introduction of Transformers in 2017, a viable alternative architecture has demonstrated the ability to match Transformer performance across multiple domains while offering fundamentally better computational efficiency. This has profound implications for the AI industry and research community.
For AI infrastructure and deployment, Mamba’s linear scalability could significantly reduce the enormous energy consumption and hardware costs associated with running large AI models. As organizations worldwide deploy AI at scale, the environmental and economic benefits of architectures that require 3× less computation and 86% less memory are substantial. This efficiency advantage is particularly relevant as AI regulation increasingly considers environmental impact and energy consumption.
For AI democratization, Mamba’s lower resource requirements could help bridge the gap between well-funded AI labs and smaller organizations or researchers in developing countries. Models that achieve comparable quality with a fraction of the computational resources make cutting-edge AI research and deployment accessible to a broader community, potentially accelerating innovation across more diverse perspectives and applications.
For future AI systems, the survey suggests that the optimal architecture may not be pure Mamba or pure Transformer, but thoughtful hybridizations that leverage each architecture’s strengths. Attention mechanisms excel at certain reasoning tasks and global pattern recognition, while Mamba excels at efficient long-range processing and memory-constrained deployment. The future likely belongs to architectures that can dynamically select the most appropriate computation pattern for each layer and each task, combining the best of both paradigms. Our analysis of agent skills for large language models explores how these architectural advances translate into practical AI agent capabilities.
📊 Explore this analysis with interactive data visualizations
Frequently Asked Questions
What is the Mamba architecture in deep learning?
Mamba is a deep learning architecture based on structured state space models (SSMs) that provides an alternative to Transformers. It achieves comparable modeling capabilities while maintaining linear scalability with sequence length, compared to Transformers’ quadratic complexity. Mamba introduces a selective mechanism that filters irrelevant information based on input, enabling efficient processing of long sequences.
How does Mamba compare to Transformer architectures?
Mamba offers near-linear computational complexity versus Transformers’ quadratic attention complexity, making it up to 3x faster on GPUs for long sequences. Mamba uses selective state spaces instead of attention mechanisms, consuming significantly less memory. While Transformers excel at capturing global dependencies through attention, Mamba achieves similar quality through its recurrent selective mechanism with much better efficiency.
What are state space models (SSMs) in machine learning?
State space models (SSMs) are mathematical frameworks that describe dynamic systems using hidden state variables. In machine learning, structured SSMs like S4 and Mamba adapt this framework for sequence modeling, combining benefits of RNNs (sequential processing) and CNNs (parallel computation) while achieving linear scaling with sequence length.
What applications benefit most from Mamba architecture?
Mamba excels in applications requiring long sequence processing: computer vision (2.8x faster than DeiT with 86.8% less GPU memory), natural language processing, medical imaging (UMamba for radiology), genomics, time-series analysis, point cloud processing, and recommendation systems. Any task involving lengthy sequential data benefits from Mamba’s linear scalability.
What is Mamba-2 and how does it improve on the original?
Mamba-2, proposed by Dao and Gu, reveals the connections between state space models and attention variants. It introduces a refined selective SSM architecture that achieves 2-8x speedup on language modeling tasks compared to the original Mamba, while maintaining the same linear scalability advantages over Transformers.


